
Supporting materials
Download
Download this article as a PDF





Extract DNA from fruit using household ingredients and then explore the challenges of gene sequencing by assembling a fragmented poem.
Domesticated crop plants tend to have low genetic diversity because they have usually been selectively bred from varieties that are genetically related. This cross-breeding approach produces high-yield varieties, but it can also increase susceptibility to disease and pests.[1]
Cross-breeding these domesticated strains with wild-type strains has been shown to increase genetic diversity and can produce strains with beneficial genes from their wild-type ancestors. Genome data is key here, as phenotype does not also predict genetic potential.[1]
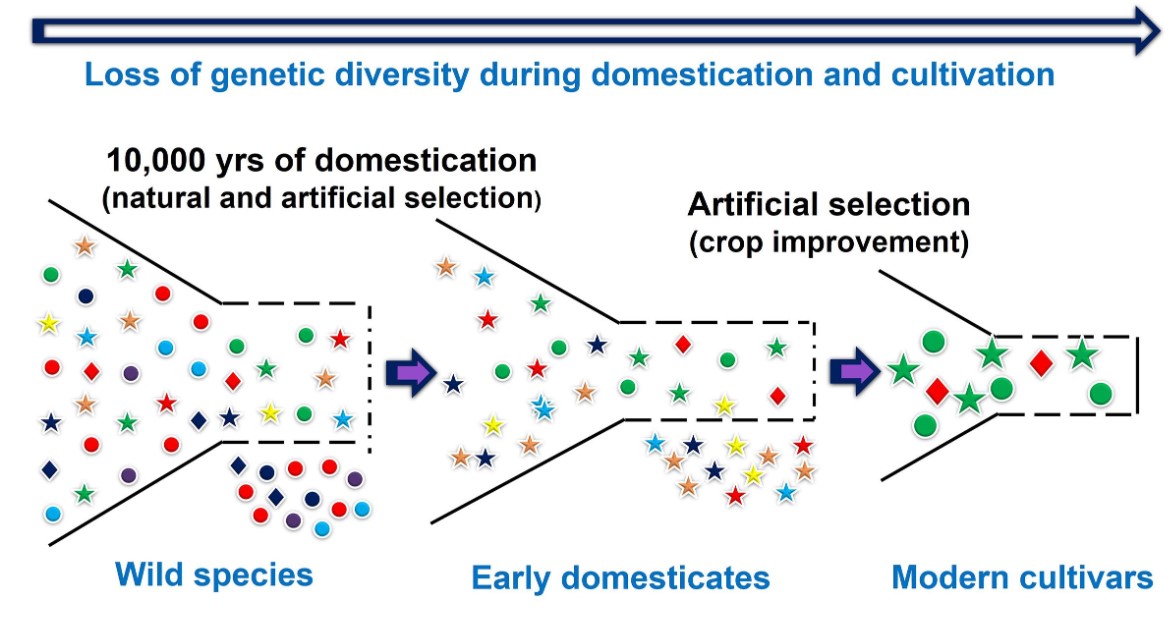
EMBL-EBI’s EnsemblPlants database contains genome assemblies and annotations for agriculturally and environmentally important crops and plants. The data is all open access and freely available to use. Database users can explore plant genomes down to the nucleotide level for a range of species, including the genes and their predicted protein structures. Users can also explore genetic variations identified from different individuals and the predicted effects those will have on the organism’s genes.
Here, we present activities to introduce some of the basic concepts of plant DNA and sequencing data to explore the curriculum topics of evolution, inheritance and variation, and bioinformatics. Students extract genetic material and explore the process of assembling genome sequences.
Then, in a second article in the next issue, students are invited to explore the genetics of food plants and crops by going on a plant treasure hunt and trying to breed the best apple! They’ll be encouraged to consider the importance of genetically diverse agricultural plants and crops, especially in the context of a growing population and changing climate.
These activities are suitable for students aged 14 and above. It is useful for students to visualize DNA as a first step; however, if DNA extraction from fruit has previously been carried out by students, they can go straight to Activity 2.
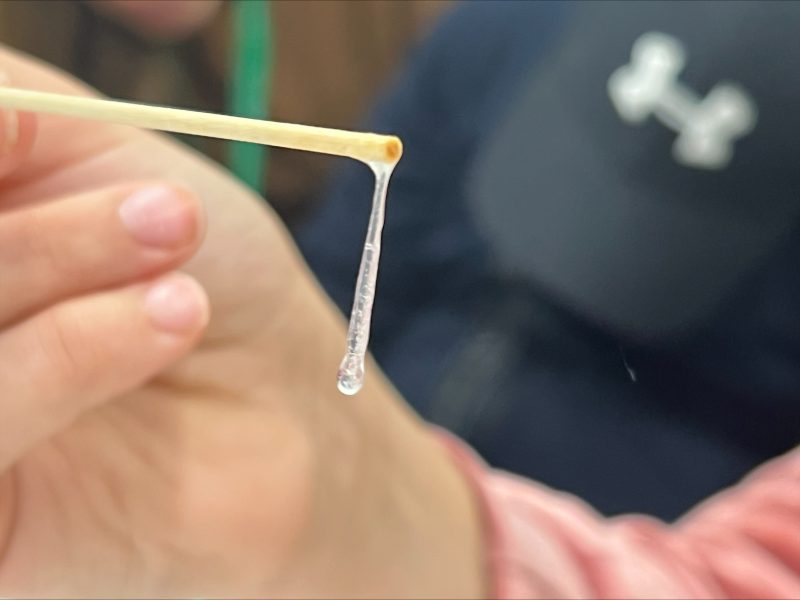
This activity provides hands-on experience of following a lab protocol and helps students to understand the following stages of DNA extraction.
– Preparation: mixing the ingredients to make the lysis buffer.
– Lysis: the cells that make up the fruit are burst open by the prepared solution, leading to the DNA being released into the liquid.
– Precipitation: alcohol is used to bring DNA out of the solution, so it appears as a gloopy solid, which can then be collected.
The DNA extraction procedure was adapted from a protocol created by Emily Angiolini, Earlham Institute. It takes around 30 min to complete.
Materials for each group:
Lysis buffer (ideally made by the teacher before the lesson)


Discuss the following questions:
Details on the extraction process can be found in the DNA extraction infosheet, which can be handed out as a summary at the end or used as an introduction at the start (in which case, students should already know the answers to many of the above questions).
Once DNA is extracted and sequenced, the sequence needs to be reassembled. We can’t currently sequence a genome from start to finish – it has to be broken up into smaller fragments. These small fragments then need to be arranged in the correct order before scientists can start analyzing the genome.
Sequencing is not yet 100% accurate, so small errors can occur. To account for this, each base is sequenced multiple times – this means that, at the end of sequencing, there will be lots of pieces of DNA sequence that need to be assembled in order. It’s like putting together a jigsaw puzzle when you have only part of the picture (if you have existing DNA sequences for comparison). If you don’t have existing sequences to compare them with, it’s like doing a jigsaw with no picture, and you have to look for sections of sequence overlap to get them in the right order – this stage is called assembly.
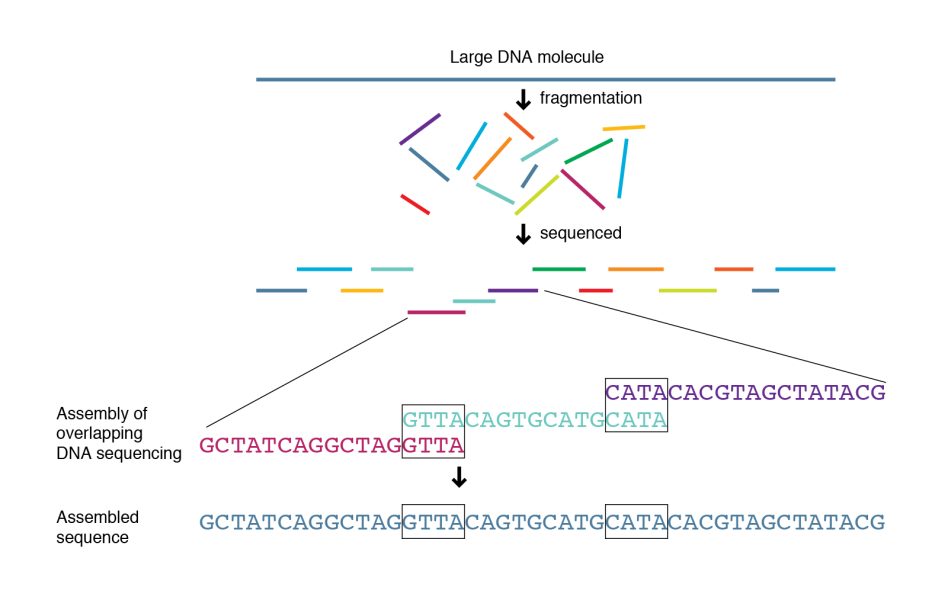
Students should work in pairs or small groups to have a go at sequence assembly using the ‘sequences’ of an assembly-themed poem about genomes.
There are three parts to this activity:
– Exercise 1: Assembly with short reads – illustrating challenges from next-generation sequencing (red words)
– Exercise 2: Aligning short reads to a reference genome (black words)
– Exercise 3: Assembly with long reads – illustrating advantages of third-generation sequencing (purple words)


Have students consider the following questions:
Then discuss the differences between this exercise and DNA sequencing. The main points are as follows.
In this activity, the assembled small fragment of a poem was written using the English alphabet, with grammar and punctuation to help us understand it. DNA assembly will typically be genomes of millions of bases, with only four different characters (A, C, G, and T), and we do not understand the ‘grammar’ of the genome. It’s a tough problem!
Imagine if there were spelling errors or typos in your fragments; this would make them even harder to use. Sometimes sequencing machines make errors, so to be certain we know what the right letter should be, we usually sequence more deeply than just the two copies used in this exercise; we might use 7, 20, 50, or more than 100 copies! It depends on how many errors you expect in the sequencing, and how perfect you need your genome to be.
Take-home messages:
[1] Tanksley SD, McCouch SR (1997) Seed banks and molecular maps: unlocking genetic potential from the wild. Science 277: 1063–1066. doi: 10.1126/science.277.5329.1063
[2] Kumar R et al. (2021) Understanding omics driven plant improvement and de novo crop domestication: some examples. Frontiers in Genetics 12: 637141. doi: 10.3389/fgene.2021.637141
Download this article as a PDF

Plants today are extremely diverse, abundant, and flamboyant. However, the first land plants, which initiated a great change in the flora and fauna on planet Earth, were very different.




A walk on the wild side: invite some ants to take a walk on your petri dish and discover how bacteria from their feet could help us reduce pesticide use.
Stroll through biological databases: Walking on chromosomes is a CusMiBio project that teaches students how to explore biological databases and…

